OpenCode: quando o agente de IA sai do chat e entra no fluxo de trabalho
A primeira fase da IA generativa foi dominada pelo chat. Abríamos uma janela, descrevíamos um problema, copiávamos um trecho de código, esperávamos uma resposta e depois voltávamos manualmente para o ambiente real de trabalho.
Esse formato foi revolucionário, mas tem um limite evidente: ele mantém a IA do lado de fora da operação.
O OpenCode aponta para outra direção. Ele não trata a IA apenas como uma caixa de perguntas e respostas. Ele coloca o agente dentro do ambiente onde o trabalho técnico acontece: o terminal, o editor, o repositório, os arquivos, os comandos, as permissões e as ferramentas externas.
A diferença parece pequena, mas é estrutural.
Quando a IA conversa, ela ajuda. Quando ela opera com contexto, ferramentas e governança, ela começa a virar infraestrutura de trabalho.
O que é o OpenCode
O OpenCode é um agente de programação open source desenhado para funcionar no terminal, no IDE e também em uma aplicação desktop. Em vez de ser apenas um assistente que responde perguntas sobre código, ele pode explorar uma base, propor mudanças, editar arquivos, rodar comandos e trabalhar com modelos diferentes.
A documentação oficial informa que o OpenCode usa o AI SDK e o Models.dev para suportar mais de 75 provedores de LLM, além de modelos locais. Isso significa que o agente não está preso a um único fornecedor de IA.
Essa característica muda a forma de avaliar a ferramenta. O valor principal do OpenCode não está apenas em “qual modelo ele usa”, mas em como ele organiza o ambiente de execução ao redor do modelo:
- contexto do projeto;
- ferramentas disponíveis;
- permissões de escrita e execução;
- agentes com papéis diferentes;
- skills reutilizáveis;
- provedores intercambiáveis;
- governança do fluxo agentivo.
Em outras palavras: o OpenCode é menos um “chat para programadores” e mais uma camada operacional para agentes de código.
O problema dos chats de IA no trabalho técnico
O chat é excelente para raciocinar, explicar, resumir e gerar alternativas. Mas ele é fraco quando o trabalho exige continuidade operacional.
Em programação, isso aparece rapidamente. O desenvolvedor precisa explicar o contexto, colar arquivos, copiar respostas, aplicar patches, rodar testes, voltar com logs, pedir ajustes e repetir o ciclo. O gargalo deixa de ser a inteligência do modelo e passa a ser a fricção entre o modelo e o ambiente real.
O mesmo problema existe fora da programação.
Em engenharia, construção civil, automação de processos e gestão técnica, boa parte do trabalho não é apenas “responder uma pergunta”. É abrir documentos, interpretar padrões, consultar histórico, criar chamados, atualizar tarefas, gerar registros, comparar versões, aplicar procedimentos e deixar rastreabilidade.
A pergunta relevante passa a ser:
> Como tirar a IA da janela de conversa e colocá-la dentro do fluxo real de trabalho, sem perder controle?
O OpenCode é interessante justamente porque mostra uma resposta prática para essa pergunta.
O agente como operador de ambiente
Um agente útil precisa de mais do que um bom modelo. Ele precisa de ambiente.
No caso do OpenCode, esse ambiente inclui o repositório, o terminal, os arquivos, os comandos e a configuração do projeto. Isso permite que o agente aja com base no estado real do trabalho, não apenas em uma descrição parcial enviada pelo usuário.
Esse é um salto importante.
Um assistente convencional pode dizer:
> “Você provavelmente precisa alterar esta função.”
Um agente operacional pode dizer:
> “Eu encontrei a função, verifiquei onde ela é chamada, propus um plano, editei os arquivos, rodei os testes e mostrei o diff.”
Essa diferença é o núcleo da nova geração de ferramentas de IA. O ganho não vem apenas de respostas melhores. Vem da redução do atrito entre intenção, execução e verificação.
Agentes com papéis diferentes
Um dos pontos mais importantes do OpenCode é a separação entre agentes com funções e permissões distintas.
A documentação do OpenCode trabalha com agentes como `build`, `plan`, `general` e `explore`. A ideia é simples e poderosa: nem todo agente deve poder fazer tudo.
Um agente de planejamento pode analisar a base e propor caminhos sem modificar arquivos. Um agente de construção pode editar, executar comandos e implementar mudanças. Subagentes podem explorar partes específicas do problema.
Essa separação importa porque autonomia sem governança é risco.
Em qualquer operação técnica séria, o problema não é apenas “a IA consegue fazer?”. A pergunta correta é:
- ela pode fazer isso agora?
- com quais permissões?
- em qual escopo?
- deixando qual registro?
- com qual possibilidade de revisão?
- usando quais dados?
Esse modelo é diretamente transferível para outras áreas.
Em uma operação de construção civil, por exemplo, poderíamos ter agentes com papéis diferentes:
- um agente que lê reuniões e identifica tarefas;
- um agente que transforma decisões em chamados;
- um agente que consulta documentos técnicos;
- um agente que atualiza cronogramas;
- um agente que revisa integrações;
- um agente que apenas planeja, sem executar alterações.
O princípio é o mesmo: agentes não devem ser “superusuários genéricos”. Eles devem operar com papéis, limites e procedimentos.
Skills: conhecimento operacional reutilizável
Outro ponto essencial é o suporte a skills.
No OpenCode, skills são definidas por arquivos `SKILL.md`. Elas funcionam como instruções reutilizáveis que o agente pode carregar conforme a tarefa.
Esse detalhe é mais importante do que parece.
Na prática, uma skill transforma conhecimento tácito em procedimento executável pelo agente. Em vez de explicar toda vez como revisar uma API, como criar um changelog, como abrir um chamado ou como testar uma integração, a equipe documenta o procedimento uma vez e o agente passa a ter acesso a esse padrão.
Isso aproxima agentes de IA de algo que empresas já conhecem bem: procedimentos operacionais.
A diferença é que, agora, esses procedimentos não são apenas lidos por pessoas. Eles também podem orientar sistemas que executam trabalho.
Para empresas de engenharia, construção e tecnologia aplicada, esse é um ponto decisivo. O valor não está só em “usar IA”. Está em transformar padrões internos em instruções operáveis por agentes.
Modelos gratuitos: o laboratório real dos agentes de código
Um dos aspectos mais interessantes do OpenCode é que ele não depende de um único modelo.
A documentação oficial de modelos afirma que o OpenCode suporta mais de 75 provedores e modelos locais. Além disso, existe o OpenCode Zen, uma camada opcional com uma lista curada de modelos testados pela equipe do OpenCode.
Na versão atual da documentação do Zen, os modelos listados como gratuitos por tempo limitado são:
| Modelo no OpenCode Zen | ID de uso no OpenCode | Condição indicada na documentação | Leitura prática |
|---|---|---|---|
| Big Pickle | opencode/big-pickle | Gratuito por tempo limitado | Modelo stealth; útil para experimentação, mas com menor transparência pública. |
| Qwen3.6 Plus Free | opencode/qwen3.6-plus-free | Gratuito por tempo limitado | Forte candidato para tarefas complexas, com benchmark público alto. |
| Nemotron 3 Super Free | opencode/nemotron-3-super-free | Gratuito por tempo limitado | Interessante para contexto grande e velocidade, mas exige atenção às condições do provedor. |
| MiniMax M2.5 Free | opencode/minimax-m2.5-free | Gratuito por tempo limitado | Bom equilíbrio entre inteligência, velocidade e custo quando comparado a modelos abertos. |
Essa lista é relevante porque mostra uma mudança importante: o futuro dos agentes não depende necessariamente de escolher um único modelo vencedor. Ele depende de orquestrar modelos diferentes para tarefas diferentes.
Nem toda tarefa precisa de um modelo frontier caro. Em muitos casos, o melhor modelo é aquele que resolve bem o problema, responde rápido, custa pouco e opera dentro do nível de risco aceitável.
Comparando modelos gratuitos com proprietários
Benchmarks públicos ajudam a entender essa diferença.
O Artificial Analysis mede modelos em critérios como inteligência, velocidade, preço, janela de contexto e desempenho em tarefas agentivas. Nenhum benchmark deve ser lido como verdade absoluta, mas eles ajudam a comparar ordens de grandeza.
Alguns dados atuais são especialmente úteis para pensar o OpenCode:
| Modelo | Tipo | Índice Artificial Analysis | Velocidade | Preço de referência | Observação editorial |
|---|---|---|---|---|---|
| Gemini 3.1 Pro Preview | Proprietário | 57 | 121,4 tokens/s | US$ 2 input / US$ 12 output por 1M tokens | Muito forte, multimodal e com contexto de 1M tokens. |
| GPT-5.3 Codex xhigh | Proprietário | 54 | 68,8 tokens/s | US$ 1,75 input / US$ 14 output por 1M tokens | Modelo proprietário forte para coding agentivo. |
| Qwen3.6 Plus | Provedor aberto / modelo competitivo | 50 | 53,4 tokens/s | US$ 0,50 input / US$ 3 output por 1M tokens | Muito competitivo, mas verboso e mais lento. |
| GLM-5 Reasoning | Open weights | 50 | 75,7 tokens/s | US$ 1 input / US$ 3,20 output por 1M tokens | Forte em inteligência; referência útil para comparação com o ecossistema aberto. |
| Claude Opus 4.6 High Effort | Proprietário | 46 | 38,2 tokens/s | US$ 5 input / US$ 25 output por 1M tokens | Alta inteligência, mas caro e mais lento. |
| MiniMax M2.5 | Open weights | 42 | 92,3 tokens/s | US$ 0,30 input / US$ 1,20 output por 1M tokens | Excelente equilíbrio para uso operacional. |
| Nemotron 3 Super | Open weights / NVIDIA | 36 | 172,8 tokens/s | US$ 0,30 input / US$ 0,75 output por 1M tokens | Muito rápido, contexto de 1M tokens e perfil interessante para tarefas longas. |
| GPT-5.4 xhigh | Proprietário | 57 | 81,8 tokens/s | US$ 2,50 input / US$ 15 output por 1M tokens | Fronteira proprietária forte; mais barato que GPT-5.5, mas ainda caro e muito verbose. |
| Claude Opus 4.7 Max | Proprietário | 57 | 47,4 tokens/s | US$ 5 input / US$ 25 output por 1M tokens | Fronteira proprietária muito forte; caro, lento e muito verbose. |
| GPT-5.5 xhigh | Proprietário | 60 | 67,5 tokens/s | US$ 5 input / US$ 30 output por 1M tokens | Líder de inteligência na amostra atual; caro, verbose e com TTFT alto. |
| Kimi K2.5 | Pago de baixo custo / Open weights | 47 | 35,7 tokens/s | US$ 0,60 input / US$ 3 output por 1M tokens | Pago de baixo custo no Zen; forte custo-benefício frente aos proprietários, mas lento e verboso. |
| Kimi K2.6 | Pago de baixo custo / Open weights | 54 | 39,0 tokens/s | US$ 0,95 input / US$ 4 output por 1M tokens | Pago de baixo custo; salto relevante de inteligência sobre K2.5, mas mais lento e mais verboso. |
| GLM 5.1 | Pago de baixo custo / Open weights | 51 | 48,5 tokens/s | US$ 1,40 input / US$ 4,40 output por 1M tokens | Modelo pago de baixo custo no Zen; inteligência alta, contexto grande, mas mais caro que GLM 5 e bastante verboso. |
A leitura mais interessante não é “gratuitos vencem proprietários” ou “proprietários continuam melhores”. Essa dicotomia é pobre.
A leitura correta é outra:
> Modelos gratuitos ou de baixo custo já são bons o bastante para ocupar uma parte grande da camada operacional do trabalho agentivo.
Eles podem ser suficientes para:
- explorar uma base de código;
- explicar arquivos;
- gerar scripts auxiliares;
- sugerir refatorações;
- escrever documentação;
- fazer triagem de erros;
- operar tarefas repetitivas;
- atuar como subagentes especializados.
Já modelos proprietários de fronteira continuam fazendo sentido para decisões mais críticas, raciocínio mais difícil, tarefas longas, ambiguidades relevantes ou contextos em que a taxa de erro precisa ser menor.
O ponto é que uma arquitetura madura de agentes não precisa escolher apenas um dos caminhos. Ela pode combinar.
O que cada modelo gratuito sugere na prática
Qwen3.6 Plus Free
O Qwen3.6 Plus aparece no Artificial Analysis com índice 50, contexto de 1M tokens e suporte a texto, imagem e vídeo como entrada. No OpenCode Zen, sua variante Free aparece como gratuita por tempo limitado.
Isso o torna um candidato forte para tarefas mais complexas, especialmente quando o contexto é grande. A ressalva prática é que ele aparece como mais lento e muito verboso. Para um agente de terminal, isso pode ser bom em planejamento, mas ruim quando a tarefa pede ciclos rápidos.
Uso recomendado:
- planejamento de mudanças grandes;
- leitura de contexto extenso;
- comparação de alternativas técnicas;
- revisão de arquitetura;
- análise de documentação longa.
MiniMax M2.5 Free
O MiniMax M2.5 aparece no Artificial Analysis com índice 42, velocidade de 92,3 tokens/s, contexto de 205k tokens e licença MIT. A documentação do OpenCode Zen lista a variante MiniMax M2.5 Free como gratuita por tempo limitado.
O perfil é muito interessante para uso operacional: não é o maior índice da lista, mas combina bom desempenho, boa velocidade e preço de referência baixo.
Uso recomendado:
- exploração de base de código;
- refatorações controladas;
- geração de scripts;
- documentação;
- tarefas de rotina com boa relação entre qualidade e velocidade.
Nemotron 3 Super Free
O Nemotron 3 Super aparece no Artificial Analysis com índice 36, velocidade de 172,8 tokens/s e contexto de 1M tokens. A variante Free aparece no OpenCode Zen como gratuita por tempo limitado.
O ponto forte é claro: velocidade e contexto. Isso pode ser muito útil quando o agente precisa ler muito material, resumir, classificar, navegar em logs ou operar tarefas menos ambíguas.
Uso recomendado:
- leitura de arquivos grandes;
- triagem de logs;
- sumarização operacional;
- classificação de tarefas;
- exploração ampla antes de passar para um modelo mais forte.
Big Pickle
O Big Pickle é descrito na documentação do OpenCode Zen como um modelo stealth gratuito por tempo limitado. Isso significa que ele pode ser útil para teste e experimentação, mas não oferece a mesma transparência pública de um modelo com página clara de benchmark, especificações e comparativos.
Uso recomendado:
- testes não sensíveis;
- experimentação;
- tarefas descartáveis;
- avaliação interna antes de adoção.
Gratuito não significa sem custo
Existe uma armadilha comum na adoção de modelos gratuitos: confundir preço zero com risco zero.
A própria documentação do OpenCode Zen informa que os modelos gratuitos estão disponíveis por tempo limitado e que, durante esse período, dados podem ser usados para melhoria do modelo em alguns casos. A seção de privacidade também diferencia a política geral dos provedores e as exceções aplicáveis aos modelos gratuitos.
Isso exige uma regra prática clara:
> Modelo gratuito é excelente para experimentação, código aberto, automações não sensíveis e tarefas de baixo risco. Para código proprietário, contratos, dados de cliente, chaves, logs internos e decisões críticas, use modelos com política adequada de retenção e privacidade — ou modelos locais.
Essa discussão é central para qualquer empresa que queira usar agentes de IA de forma profissional.
O problema não é usar modelos gratuitos. O problema é usá-los sem classificação de dados, sem governança e sem distinção entre ambiente de teste e ambiente sensível.
O que isso ensina além da programação
Embora o OpenCode seja uma ferramenta para programação, sua importância vai além do código.
Ele mostra um desenho de arquitetura que pode ser aplicado a vários workflows técnicos:
1. o agente precisa conhecer o ambiente;
2. precisa ter ferramentas;
3. precisa operar com permissões;
4. precisa seguir procedimentos;
5. precisa deixar rastros;
6. precisa alternar entre modelos conforme tarefa, custo e risco.
Esse modelo serve para pensar agentes em construção civil, engenharia, gestão de obras, suporte técnico, automação documental e operação de sistemas.
Imagine um fluxo de reuniões em uma empresa de engenharia. Hoje, uma pessoa escuta a reunião, extrai decisões, identifica tarefas, cria chamados, atribui responsáveis, registra prazos e atualiza sistemas.
Um agente operacional poderia apoiar esse fluxo se tivesse:
- acesso às transcrições;
- skill para classificar demandas;
- permissão para criar itens no sistema correto;
- regra para diferenciar bug, melhoria, tarefa e projeto;
- limite para não executar ações sensíveis sem revisão;
- histórico de decisões anteriores;
- integração com documentos, quadros e cronogramas.
Essa é a mesma lógica que o OpenCode aplica ao repositório de código.
O terminal, nesse sentido, é apenas um exemplo poderoso de ambiente operacional. O conceito maior é o agente atuando dentro do sistema onde o trabalho acontece.
OpenCode dentro do VS Code: além do terminal
Um cuidado importante neste artigo é não reduzir o OpenCode ao terminal. A própria documentação oficial descreve o OpenCode como disponível em três superfícies: interface de terminal, aplicação desktop e extensão para IDE. Isso muda a percepção da ferramenta.
No VS Code, Cursor e outros editores compatíveis, o OpenCode pode ser usado como uma extensão integrada ao fluxo do desenvolvedor. A documentação oficial explica que basta rodar `opencode` no terminal integrado para começar; a extensão pode ser instalada automaticamente nesse processo ou manualmente pelo marketplace.
Na prática, isso cria uma experiência híbrida: o agente continua usando a força operacional do terminal, mas passa a conversar com o contexto visual do editor. O desenvolvedor não precisa abandonar os arquivos abertos, a seleção atual, os atalhos do IDE ou a navegação do projeto.
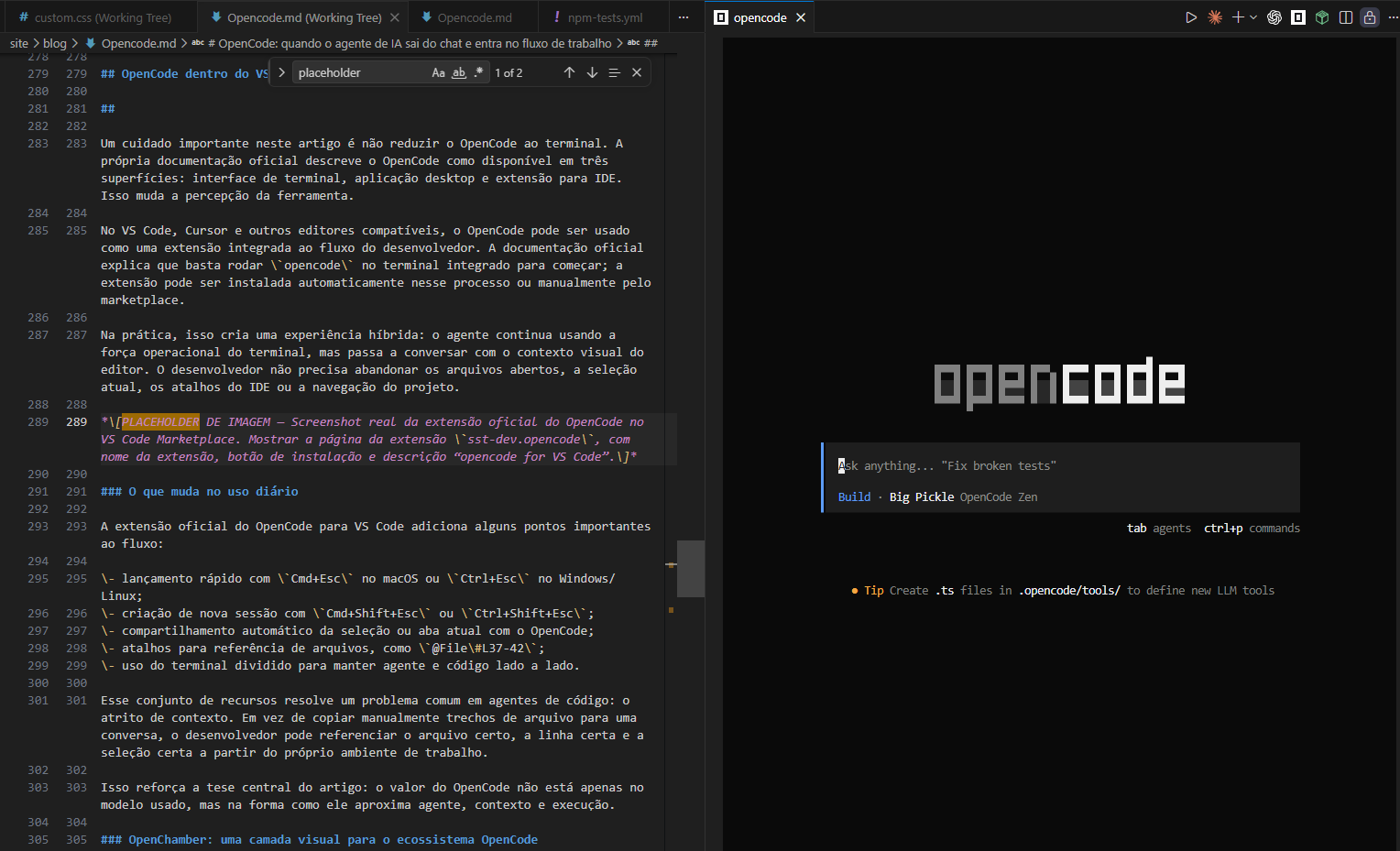
O que muda no uso diário
A extensão oficial do OpenCode para VS Code adiciona alguns pontos importantes ao fluxo:
- lançamento rápido com `Cmd+Esc` no macOS ou `Ctrl+Esc` no Windows/Linux;
- criação de nova sessão com `Cmd+Shift+Esc` ou `Ctrl+Shift+Esc`;
- compartilhamento automático da seleção ou aba atual com o OpenCode;
- atalhos para referência de arquivos, como `@File#L37-42`;
- uso do terminal dividido para manter agente e código lado a lado.
Esse conjunto de recursos resolve um problema comum em agentes de código: o atrito de contexto. Em vez de copiar manualmente trechos de arquivo para uma conversa, o desenvolvedor pode referenciar o arquivo certo, a linha certa e a seleção certa a partir do próprio ambiente de trabalho.
Isso reforça a tese central do artigo: o valor do OpenCode não está apenas no modelo usado, mas na forma como ele aproxima agente, contexto e execução.
OpenChamber: uma camada visual para o ecossistema OpenCode
Também vale citar o OpenChamber, um projeto complementar que se apresenta como uma interface desktop e web para o agente OpenCode. O projeto propõe uma experiência mais visual para revisar diffs, gerenciar agentes, acompanhar servidores de desenvolvimento e manter uma visão mais ampla enquanto a IA trabalha.
O ponto interessante do OpenChamber é que ele amplia a discussão além da oposição “terminal versus IDE”. Ele mostra que o ecossistema em volta do OpenCode está indo para múltiplas interfaces: terminal para operação direta, VS Code para o fluxo de edição, desktop/web para acompanhamento visual e até continuidade em outros dispositivos.
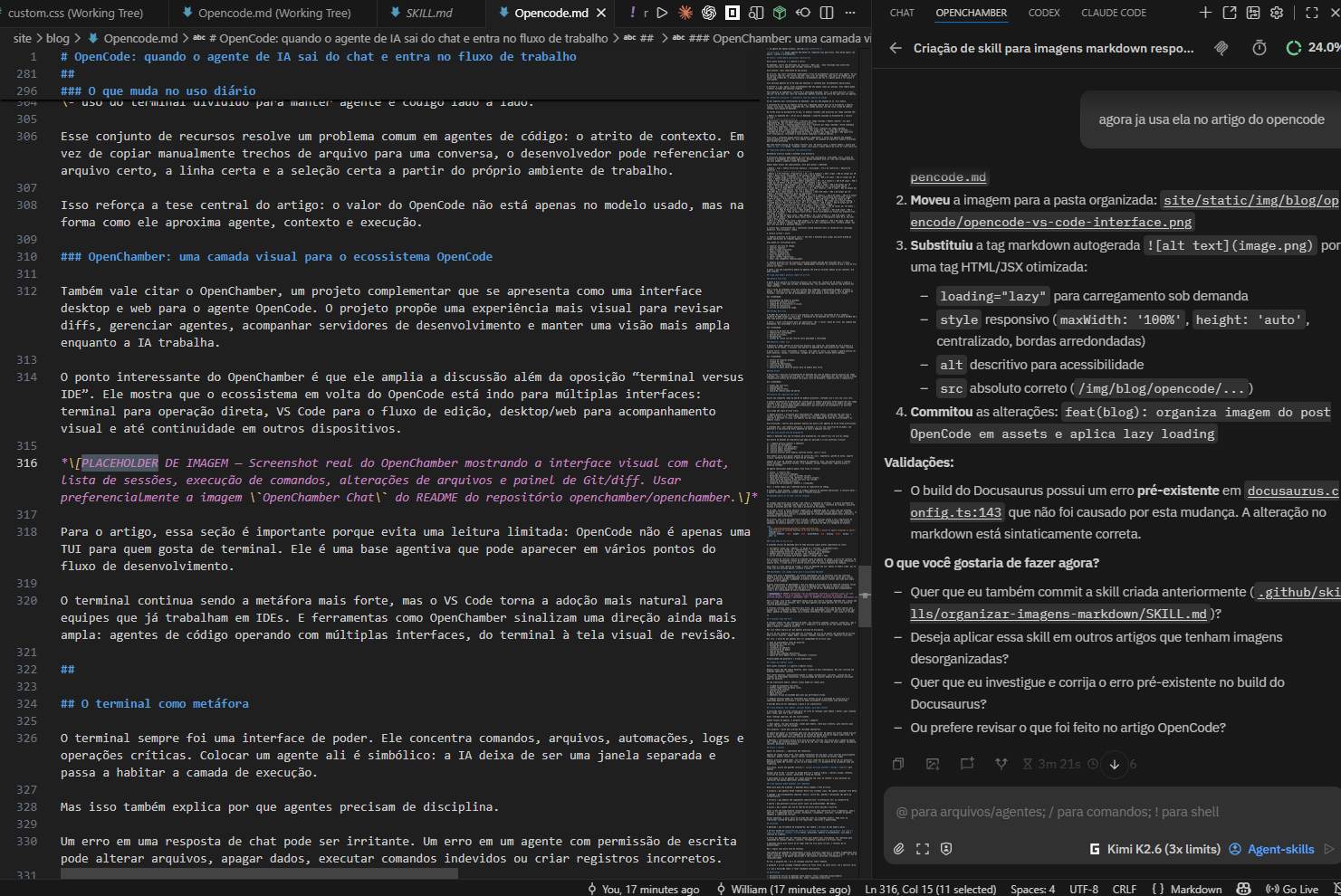
Para o artigo, essa seção é importante porque evita uma leitura limitada: OpenCode não é apenas uma TUI para quem gosta de terminal. Ele é uma base agentiva que pode aparecer em vários pontos do fluxo de desenvolvimento.
O terminal continua sendo a metáfora mais forte, mas o VS Code torna a adoção mais natural para equipes que já trabalham em IDEs. E ferramentas como OpenChamber sinalizam uma direção ainda mais ampla: agentes de código operando com múltiplas interfaces, do terminal à tela visual de revisão.
O terminal como metáfora
O terminal sempre foi uma interface de poder. Ele concentra comandos, arquivos, automações, logs e operações críticas. Colocar um agente ali é simbólico: a IA deixa de ser uma janela separada e passa a habitar a camada de execução.
Mas isso também explica por que agentes precisam de disciplina.
Um erro em uma resposta de chat pode ser irritante. Um erro em um agente com permissão de escrita pode alterar arquivos, apagar dados, executar comandos indevidos ou criar registros incorretos.
Por isso, a evolução dos agentes deve vir acompanhada de práticas como:
- modo de planejamento antes da execução;
- permissões por tipo de ação;
- revisão de diff;
- isolamento de ambiente;
- classificação de dados;
- logs de decisão;
- limites para comandos destrutivos;
- separação entre agente leitor, planejador e executor.
Produtividade sem governança é dívida operacional.
O papel dos modelos locais
Outro ponto relevante é o suporte a modelos locais.
Modelos locais não são sempre melhores, mais rápidos ou mais inteligentes. Mas eles resolvem uma dimensão importante: controle.
Para certas empresas, especialmente quando há dados confidenciais, contratos, informações de clientes ou propriedade intelectual, a possibilidade de executar modelos em ambiente controlado pode ser decisiva.
Em uma arquitetura madura, modelos locais podem ser usados para:
- triagem de documentos sensíveis;
- tarefas repetitivas de baixo risco;
- classificação interna;
- geração preliminar;
- apoio offline;
- ambientes em que privacidade pesa mais que performance máxima.
Já modelos externos podem ser reservados para tarefas em que a qualidade do raciocínio ou a capacidade agentiva justifique o envio de dados previamente classificados como permitidos.
A decisão deixa de ser ideológica e passa a ser arquitetural.
A nova pergunta: qual agente, com qual modelo, para qual tarefa?
A discussão sobre IA ainda costuma girar em torno de rankings: qual modelo é melhor, qual responde mais rápido, qual tem o maior benchmark.
Esses rankings importam, mas são insuficientes.
Quando falamos de agentes, a pergunta correta é composta:
> Qual agente, com qual permissão, usando qual modelo, sobre qual contexto, para executar qual tarefa, com qual nível de revisão?
Essa pergunta é muito mais próxima da realidade empresarial.
Um agente que apenas lê documentos pode usar uma configuração. Um agente que altera código precisa de outra. Um agente que cria chamados em um sistema de gestão precisa de regras específicas. Um agente que opera dados sensíveis precisa de restrições mais fortes.
O OpenCode é interessante porque torna essa discussão concreta. Ele mostra que a camada de agente não é apenas uma interface bonita em cima de um LLM. Ela é uma composição entre modelo, ferramenta, contexto, permissão e procedimento.
Riscos e limites
Apesar do potencial, é importante não romantizar.
Agentes de código ainda erram. Eles podem interpretar mal uma base, criar soluções excessivamente complexas, quebrar testes, ignorar efeitos colaterais ou se perder em tarefas longas.
Modelos gratuitos podem mudar, sair do ar, alterar condições de uso ou deixar de ser gratuitos. Benchmarks podem não refletir um caso de uso específico. E a documentação de provedores muda com frequência.
Além disso, existe uma questão cultural: equipes precisam aprender a delegar trabalho para agentes.
Delegar para IA não é escrever um prompt genérico e esperar mágica. É definir escopo, contexto, critérios de aceite, limites, permissões e forma de revisão.
A maturidade no uso de agentes será menos parecida com “usar um chatbot” e mais parecida com “gerenciar uma equipe operacional automatizada”.
O que empresas podem aprender com o OpenCode
Mesmo para quem não programa, o OpenCode deixa algumas lições práticas.
A primeira é que agentes devem trabalhar dentro dos sistemas reais, não apenas responder fora deles.
A segunda é que procedimentos importam. Skills, instruções, padrões e permissões são parte da infraestrutura.
A terceira é que modelos são componentes substituíveis. O diferencial está na orquestração.
A quarta é que governança precisa nascer junto com produtividade. Não depois.
A quinta é que o ganho real vem da redução de atrito entre decisão e execução.
Essas lições são especialmente relevantes para setores como construção civil e engenharia, onde a operação é fragmentada entre reuniões, documentos, cronogramas, planilhas, sistemas de gestão, chamados e comunicação informal.
Nesses ambientes, o maior valor da IA pode não estar em “responder melhor”. Pode estar em transformar informação dispersa em ação registrada, rastreável e padronizada.
Conclusão
O OpenCode é uma ferramenta de programação, mas também é um sinal de uma mudança maior.
A IA está saindo da interface de conversa e entrando nos ambientes operacionais. Ela começa a lidar com arquivos, comandos, ferramentas, permissões, modelos e procedimentos. Isso muda a natureza do trabalho.
O futuro dos agentes não será definido apenas pelo modelo mais inteligente. Será definido pela capacidade de combinar modelos, contexto, ferramentas e governança em fluxos reais.
O OpenCode mostra esse futuro em um lugar onde ele fica muito visível: o terminal de um desenvolvedor.
Mas a lógica vale muito além do terminal.
Toda empresa que depende de conhecimento técnico, processos repetíveis e sistemas fragmentados deve prestar atenção. Porque a próxima vantagem competitiva talvez não esteja em ter acesso à IA, mas em saber transformá-la em agente operacional — com contexto, permissão, procedimento e responsabilidade.
No fim, a pergunta não é se a IA consegue conversar sobre trabalho.
A pergunta é se ela consegue trabalhar dentro do fluxo certo, do jeito certo, com o controle certo.
É aí que a discussão começa a ficar realmente interessante.
Referências
- Documentação oficial do OpenCode sobre modelos: https://opencode.ai/docs/models/
- Documentação oficial do OpenCode Zen: https://opencode.ai/docs/zen/
- Artificial Analysis — Qwen3.6 Plus: https://artificialanalysis.ai/models/qwen3-6-plus
- Artificial Analysis — MiniMax M2.5: https://artificialanalysis.ai/models/minimax-m2-5
- Artificial Analysis — NVIDIA Nemotron 3 Super: https://artificialanalysis.ai/models/nvidia-nemotron-3-super-120b-a12b
- Artificial Analysis — GLM-5 Reasoning: https://artificialanalysis.ai/models/glm-5
- Artificial Analysis — Gemini 3.1 Pro Preview: https://artificialanalysis.ai/models/gemini-3-1-pro-preview
- Artificial Analysis — GPT-5.3 Codex: https://artificialanalysis.ai/models/gpt-5-3-codex
- Artificial Analysis — Claude Opus 4.6: https://artificialanalysis.ai/models/claude-opus-4-6
- Documentação oficial do OpenCode sobre IDE: https://opencode.ai/docs/ide/
- OpenCode — Visual Studio Marketplace: https://marketplace.visualstudio.com/items?itemName=sst-dev.opencode
- OpenChamber — repositório oficial: https://github.com/openchamber/openchamber